Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Qu'est ce que le NLP ? Quelles sont les méthodes, à quoi servent-elles ? Quels sont les outils ? Quels algorithmes sont à utiliser ? C'est un univers dont les applications nous entourent tous les jours et qui est à la croisée de l'informatique, de l'IA et des sciences linguistiques. Nous vous expliquons tout ici.
Tout a commencé dans les années 50 pendant la Guerre Froide, avec des systèmes de règles permettant de traduire des textes du Russe à l’Anglais. Dans les années 60, les premiers agents conversationnels font leur apparition et permettaient de reformuler et paraphraser des phrases qu’on leur rentraient.
C'est dans les années 80 que l'on est rentré en complexité. Les chercheurs ont souhaité fabriquer des systèmes qui n'utilisaient pas uniquement des règles, mais aussi les statistiques. Aujourd'hui, et depuis 2016, on a commencé à utiliser du Deep Learning avec des nouvelles architectures de modèles qui ont contribué à dynamiser cette discipline. Aujourd’hui les applications poussées de l'Intelligence Artificielle et du traitement du texte nous entourent tous les jours : le plus célèbre modèle de NLP est bien sûr ChatGPT !
De quels cas d’usages parle-t-on ?
Analyse de sentiments : très utilisé sur les réseaux sociaux pour comprendre si un message est positif ou négatif, nous en entendons souvent parlé autour des campagnes électorales !
Chatbot : vous assiste durant votre navigation sur un site internet !
Assistant vocal : Siri , Alexa, Google, nous les connaissons.
Traduction automatique par IA : Google Translate, Deepl. D'autres services Gmail permettent de suggérer le mot suivant sur un mail.
Moteur de recherche : on simplifie les recherches par la recommandation.
Classification de texte : savoir si un email est considéré comme un spam ou pas.
Un cas d’usage de Datalyo
Datalyo, un des leaders du conseil en Data à Lyon a d'ailleurs travaillé sur un de ces use cases avec un client opérateur téléphonique. Celui-ci reçoit en effet beaucoup de demandes dont les réponses se trouvent très souvent dans des FAQs, ou sur le compte client. Un temps considérable des conseillers est alloué à cette assistance, alors qu'il serait préférable de les réaffecter sur des affaires plus importantes. Nous avons donc un besoin d'automatisation pour une partie de ces réponses.
Par exemple, avec la question posée par un utilisateur : "Comment est-ce que je peux utiliser mon forfait au Canada ?", nous travaillerons en 2 étapes :
1 - identifier le thème de la question avec les mots clés apparents de #forfait #canada
2- apporter la réponse : l’idée sera ici d’aiguiller au mieux le client de l'opérateur téléphone vers la source d'une information qu’il a déjà, en l’occurence son contrat
D’un point de vue plus technique
On a l’habitude en Data Science de traiter des données structurées. On peut alors se poser la question du traitement de caractère graphique : du texte. Beaucoup de techniques existent déjà pour réaliser des pré-traitements sur ces données textuelles. Nous vous proposons ici une première boîte à outils nous aidant à bien se préparer, avant même de modéliser :
Tokénisation : découper des phrases ou un corpus de texte en mots
Retrait des stop words, ces mots qui n’apportent pas forcément beaucoup d’informations au sens de la phrase : 'Le', 'Et' etc
Stemming : supprimer les suffixes, et transformer un mot à son radical pour faciliter l’analyse
Lemming : faire en sorte que des mots qui soient dérivés soient représentés de la même manière. Par exemple pour un nom commun on va le représenter par le masculin singulier. Pour le verbe, il s'agira du radical.
Part OS Tag : identifier des groupes grammaticaux pour être capable d’identifier des noms, des adjectifs, des adverbes selon le contexte de la phrase.
Reconnaissance d’entité nommée : détecter des noms propres (lieux, personnes) par exemple pour un contrat, y extraire les informations pertinentes. Dans l'exemple du client de Datalyo, il s'agirait par exemple du mot "Canada".
Comment implémenter cela ?
En Python ! Il existe notamment 2 libraires complémentaires :
NLTK : permet de faire ces pré-traitements
Spacy : permet de réaliser ces taches avec des algorithmes pré-entrainés
Ici, un mot devient un vecteur mathématique sur lequel on va entraîner des modèles. Chaque mot va être associé à une position dans la phrase. S'il réapparaît plus tard, le mot sera ré-encodé de la même manière. Ainsi, la machine va pouvoir reconstituer avec des données numériques les phrases, créant ainsi un dictionnaire.
Parlons des algorithmes et modèles
Avoir des vecteurs de mots ne suffit pas, et plusieurs approches du traitement du texte existent :
Le Word Embedding : au lieu d’avoir un vecteur vide (0 si le mot est inexistant et 1 s'il existe), nous allons plutôt calculer la probabilité qu’il y ait d’autres mots dans cette phrase, permettant d’asseoir le contexte de la phrase. Mais cette méthode peut être limitante pour des phrases complexes.
Réseaux de neurones récurrents et LSTM : permettent de tenir compte de la position des mots dans une phrase, un concept très important qui influence beaucoup des résultats
GPT 2/3 - BERT : Ces modèles sont considérés comme l'état de l'art en NLP. Ces techniques de modélisations font leur apparition en 2016-2018, avec beaucoup de modèles pré-entrainés sur des corpus de textes volumineux, permettant aux Data Scientists de ne pas partir de 0 lorsqu'ils modèlisent.
Le Word Embedding
Cette méthode permet de conceptualiser un mot en le vectorisant ! Revenons à la notion de vecteur et prenons un exemple :
La ville de Lyon est une très belle ville.
Si précédemment le mot Lyon a été associé à d’autres éléments comme par exemple Rhônes Alpes, ou Fourvière, le modèle le comprendra comme nom de ville.
Les vecteurs peuvent aussi avoir une signification ! Par exemple ici : vecteur king - vecteur man + vecteur Woman = le mot Queen
Mais cette méthode ne permet pas tenir compte de la position des mots dans une phrase, ici avec 2 exemples :
Je ne recommande pas ce produit qui est mauvais
Je recommande ce produit qui n’est pas mauvais
Nous réalisons ici l'importance pour la machine de comprendre la position du mot dans une phrase !
Réseaux de neurones
Ces derniers permettent de tenir compte de l’ordre des mots sans perdre la signification des mots précédents !
Prenons ici un exemple : « Comment ça va ? » Avec le vecteur du mot « ça » , nous allons essayer de prédire le mot suivant en tenant compte du mot précédent « Comment » .
C’est une technique de Deep Learning qui permet d’apporter du contexte mais aussi de tenir compte de la temporalité, l'ordre d'apparition des mots dans une phrase. A noter que dès qu’il y a une erreur, nous allons devoir ré-ajuster le modèle pour être au plus proche d’une bonne performance. Cette technique fonctionne donc bien pour des phrases assez courtes car est de mémoire assez courte, mais rélève de plus faibles performances pour des phrase plus longues.
Ce modèle, lui, permet de palier au problème de mémoire, car il retient les informations importantes en oubliant le reste de la phrase, moins primordial pour la compréhension de la phrase. Ce modèle se découpe en 3 étapes :
Forget Layers : une couche qui doit apprendre ce qu’elle doit oublier de la cellule précédente
Input gate layer : une couche permettant d'extraire l’information de la donnée courante et décider ce que sera le prochain mot
Output Gate : une couche calculant la sortie, c’est a dire le vecteur suivant
Un problème relève ici de la rapidité de calcul. Dans le cadre d'une traduction automatique ou sur des applications mobiles, un résultat est attendu très rapidement.
GPT 2 & 3 by Open AI
Ces modèles sont l'état de l'art de ce qui se fait en NLP, avec une architecture encodeur - décodeur. Celle-ci permet de s’affranchir des problèmes de différentes tailles entre l’entrée et la sortie. Le modèle se découpe en 2 étapes :
Encoder : permet d'avoir une représentation de la phrase en taille fixe. Peu importe le nombre de mots en entrée, on aura toujours le même nombre de mot en sortie
Décodeur : Cela va nous permettre de générer des traductions étape par étape
Nous parlons ici de couches d’attention qui résolvent le problème que l'on a lorsque l'on ne sait pas à quel mot une information est liée.
En exemple : La voiture est sur la route, elle est glissante - "glissante" se rapporte ici à la route
La voiture est sur la route, elle va vite - "vite" se rapport à la voiture
La couche d’attention va ici permettre de lier un mot précis à la bonne information.
Le transfert Learning
En 2017, Google est venu encore améliorer ce mécanisme de couche d'attention avec les modèles BERT. Plus que des couches d’attention, les mots vont tous regarder ses voisins.
Les modèles sont entrainés sur des millions de textes pour prédire les mots suivants, mais ils deviennent très rapidement difficiles à utiliser pour une entreprise lambda en terme de capacité de calcul. La solution ? Le Transfer Learning !
De la même manière dans l'analyse d'images, l'objectif est d'adapter les poids calculés et affecté à chaque mot afin d'adapter le modèle.
Dans le modèle GPT construit par le laboratoire Open AI, la traduction de textes a pu énormément gagner en performance.
Pour les cas d'usage hors traduction, l’approche couche d’attention avec encodeur et décodeur la plus performante.
En 2018, le modèle BERT a également changé sa manière d'apprendre. Les développeurs de ce modèle considèrent maintenant que BERT apprendra bien mieux en cachant les éléments inutiles. In fine, ces modèles performent mieux pour de la prédiction de mots suivants (Gmail a d’ailleurs mis ceci en place dans son service !). Ces modèles sont majoritairement entraînés sur des textes en anglais.
Et comment travailler sur du Français ? Facebook a repris la travail de Google sur BERT pour créer des modèles qui permet de traiter du texte en Français : CamemBERT ou flauBERT.
Comparer les différents modèles de NLP
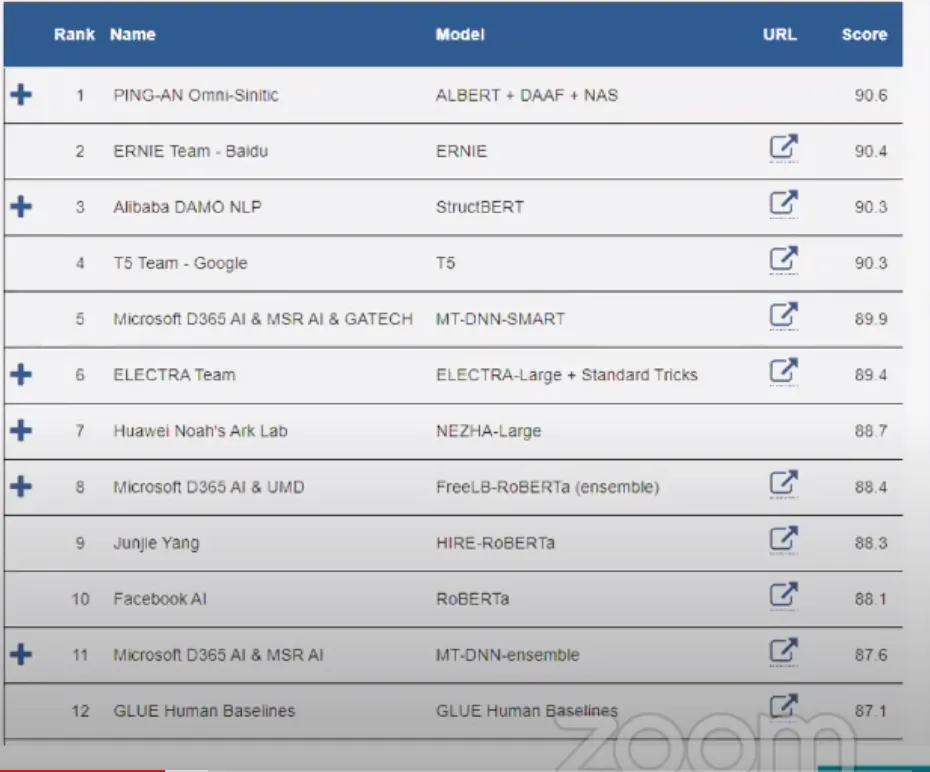
Le Benchmark GLUE permet de comparer les différents modèles de NLP. A retenir de ce classement ?
Les modèles BERT faits par Google arrivent dans les premiers, avec les modèles développés par les chinois Alibaba notamment.
Egalement, on relève que la baseline de la performance humaine n’arrive qu’en 12e position, après les différents modèles de Deep Learning !
Le classement GLUE sur les meilleurs algorithmes de NLP
Le NLP, et demain ?
Comment évaluer ces performances ? Avec le nombre de paramètres sur lesquels sont pré-entrainés ces modèles ! On remarque notamment que GPT-1 est entrainé sur 100 millions de paramètres, soit le plus haut niveau de paramètres utilisés dans les modèles d’imagerie.
Aujourd’hui, GPT-3 qui est sorti en 2020, on a 20 milliards de paramètres ! Nous vous le disions plus haut, ces modèles posent notamment des problèmes de déploiement, lorsque l'on veut des réponses rapides (traduction automatique) ou que l'on travaille sur des versions d'applications mobiles.
Conclusion
En 2019, la startup Hugging Face a créer un modèle BERT basé uniquement sur 66 millions de paramètres, rendant le déploiement plus accessible: DistillBERT.
En somme, il demeure aujourd'hui beaucoup d’ambiguïtés pour acquérir une compréhension globale du traitement du texte par la Data Science. Des chercheurs s’intéressent par exemple à la manière dont un enfant apprend !
D'autres se posent la question de la simplification que l'on réalise du langage lorsqu'il est parlé. Par exemple, à la question posée à un assistant vocal « trouve-moi un italien à Londres » , on parle ici bien d’un restaurant, mais l’assistant va manquer de contexte.
N'hésitez pas à aller consulter le site d’ Hugging Face, vous y trouverez la liste de tous les modèles de NLP.
Myriam est l'une des toutes premières recrues de Jedha Bootcamp. Passionée par les sujets d'éducation, elle a rejoint Jedha à ses débuts, juste après avoir été diplômée de l'ESSEC. Elle s'est rapidement spécialisée en Marketing et a été notre Head of Marketing jusqu'à la fin de l'année 2022.
Le Deep Learning est un domaine qui se développe de plus en plus et qui est très utilisé en entreprise. Nos formations en Data Science vous permettent de devenir autonome sur cette notion de Deep Learning.
Machine Learning & Deep Learning sont devenus des termes extrêmement utilisés dans le cadre de nos activités, avec des applications toujours plus nombreuses. Lorsque l’on parle de Deep Learning, nous parlons d’algorithmes capables de mimer les actions du cerveau humain grâce à des réseaux de neurones d’où le terme d’Intelligence Artificielle.
Vous souhaitez vous reconvertir dans la Data ? Découvrez les meilleures offres de formation en Machine Learning pour réussir votre projet professionnel !
Le Deep Learning est une forme d'IA dérivée du Machine Learning. Le Deep Learning est capable d'imiter le cerveau humain grâce à des réseaux de neurones artificiels.
Vous réfléchissez à vous former en Machine Learning ? Vous voulez comprendre comment fonctionne l’apprentissage automatisé ? Jedha vous dit tout ce qu’il faut savoir sur cette branche de l’Intelligence Artificielle en plein boom !
.webp)





.webp)